![[原创工具] 本地语音转文字 STT Powered by Faster Whisper CPU可用-二楼后座](https://cdn.ele.ac.cn/wp-content/uploads/2024/09/免费语音转文字工具-支持10种语言-Voice-Transcriber-Bot-Featured-Image-300x200-1.jpg)

v0.2更新
- 应要求换掉了识别精度较差的base,增加了small和large两种模型;
- 现在你可以在识别过程中终止操作了;
- 保存结果可以选择位置了;
- 更改模型默认保存位置为当前文件夹 model 目录下。
提醒:
根据用户反馈的问题,现更新回复如下
- 兼容性:程序需要在win10 64bit以上系统版本使用,win7、xp等操作系统不支持;同时,部分【奔腾、赛扬低端处理器】因缺少所需指令集可能无法正常使用。
- 选择模型问题:建议在使用large模型时,切换精度选择框为float32;其他两款模型建议使用int8即可。
- 网络问题:模型体积较大,请确保网络环境稳定,若出现无法下载,连续失败等问题,建议删除同目录下的models文件夹重试。
若以上回答没有解决问题,请回帖反馈,附上console(那个黑框框)里的输出内容,方便排查。
背景
最近接到一个需求,需要把录音转换为文字,一看网上几款常用的工具,想不到都是收费的;论坛里面找了找,发现基本上都需要云端api,仅有的几个本地的都需要使用GPU中的cuda计算。因此,开发了这么一款语言转文字的小工具,基于Faster Whisper模型,在cpu上也能达到不错的效果。
使用方式
双击文件打开,在左上角选择模型,左下角选择推理方式与精度(cpu推荐int8,速度更快)。
若没有支持cuda的GPU请不要选择GPU,否则会崩溃(原本想导入pytorch库判断cuda_is_available的,但是这样打出来的包会把一整个pytorch一起打包进去,太大了,后来就没这么处理)
首次使用需要下载模型,进度在console中可见,请耐心等待。
测试截图
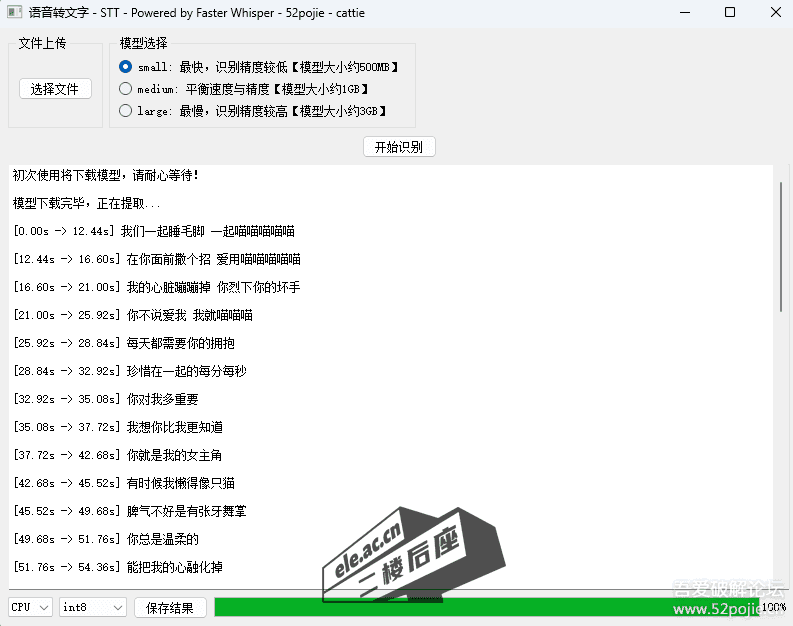
下载地址
技术栈
使用了PyQt5开发界面,使用Faster Whisper中的ctranslate2进行推理,使用opencc对提取出的繁体中文进行翻译。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
THE END

-Featured-Image-300x200-1.jpg)



















暂无评论内容